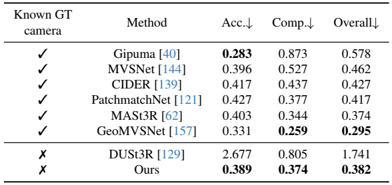
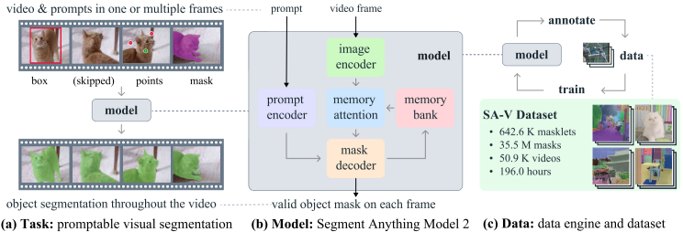
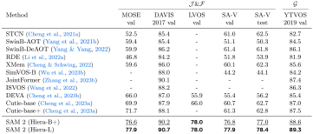
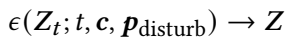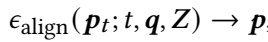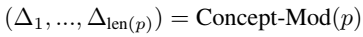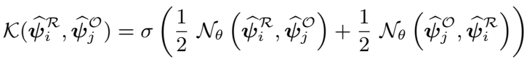problem and position: continuous-to-discrete action tokenization for LLM-like VLA
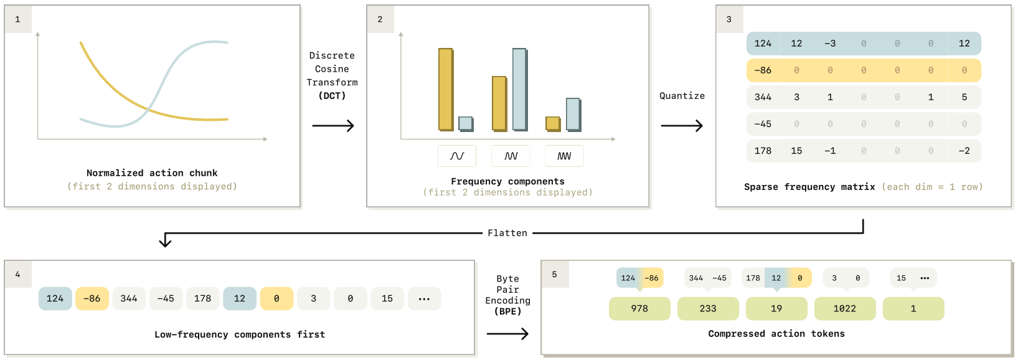
method overview: transfer action chunks to frequency space and compress into tokens
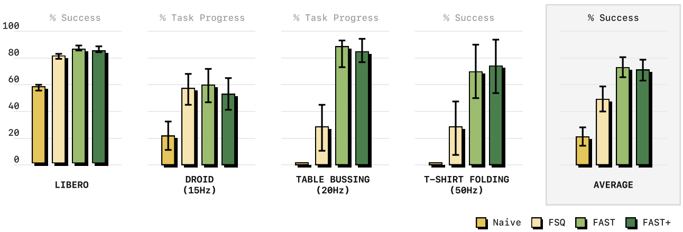
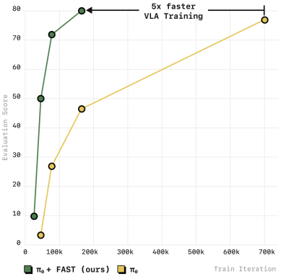
results: match diffusion VLA but more efficient to train
method details:
naive tokenization is per-dimension per-timestep binning scheme, but can lead to trivial solution for action chunks as simply copying the most recent action token, also lead to many tokens
use DCT to transform action chunk into frequency space, then use BPE to compress into tokens
since BPE needs training for each dataset, train a universal action tokenizer across many datasets for 1-second action chunks
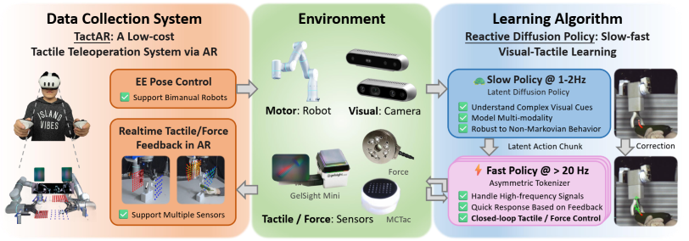
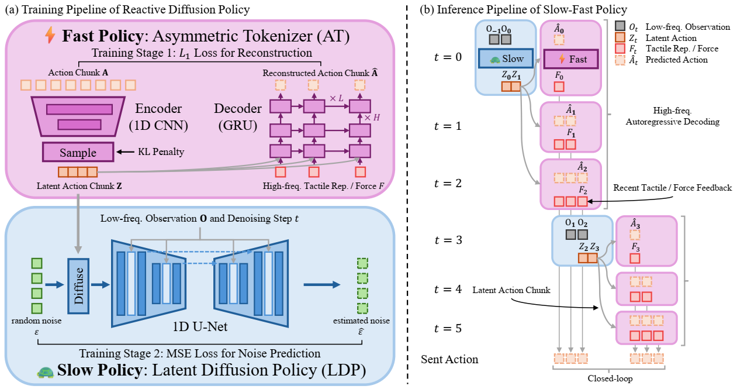
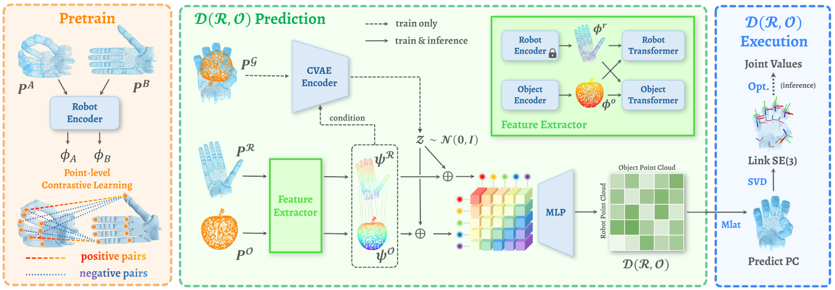
problem and position: hierarchical visual-tactile imitation learning
method overview: teleoperation with tactile/force feedback shown in AR, slow vision latent diffusion policy and fast tactile/force reactive decoder
teaser:
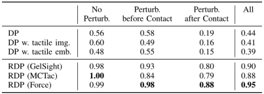
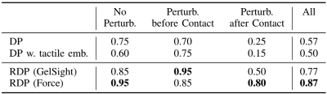
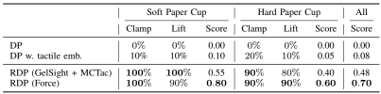
results:
method details:
use Quest3 to teleoperate, show tactile/force by AR
encode tactile marker deformation field by PCA into a compact vector, encode force by directly using the 6D vector
fast policy as VAE to encode real action chunk into latents, which can be decoded with high-freq tactile/force, < 1ms
slow policy as Diffusion Policy on latent actions, ~100ms
insight of separating slow-fast policy: fast policy’s asymmetric design of decoding with tactile/force feedback leaves reactive behaviors to fast policy decoding, while latent actions just care about general tendency instead of reactive behaviors
information: RSS 2025 outstanding systems paper finalist Shanghai AI Lab (Jiangmiao Pang)
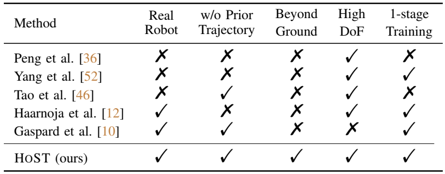
problem and position: humanoid standing-up control from diverse postures
method overview: train PPO in simulation with several techniques
teaser:
results:
method details:
use PPO to train Unitree G1 in Isaac Gym
observation as robot’s proprioceptive states
action as delta joint angles
use PD controller to track action as torque-based actuation
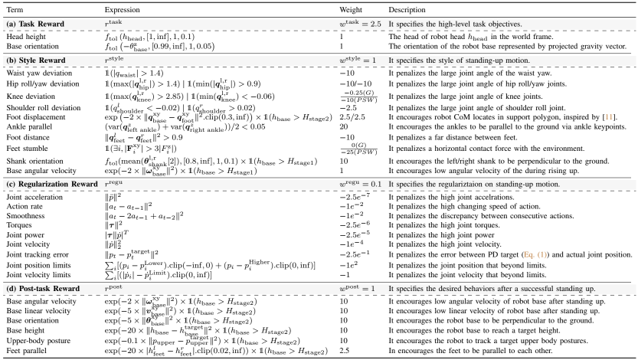
divide into 3 stages as righting, rising and standing according to the height, activate different reward functions at each stage, and design 4 groups of reward functions, use multiple critics to balance
add pulling force in initial training and progressively decrease the magnitude, to help RL exploration challenge
action scale to constrain violent motion and L2C2 loss for motion smoothness regularization
design 4 terrains to diversify the starting postures
information: RSS 2025 outstanding demo paper UCBerkeley (Pieter Abbeel)
problem and position: open-source infrastructure for robotics GPU RL
method overview: build upon MuJoCo XLA for GPU simulation, integrate batch rendering with Madrona for GPU rendering, support DeepMind control suite and locomotion and manipulation environments with diverse robots
teaser:
results: whole pipeline from setup to training takes few minutes on a single GPU
information: SIGGRAPH 2025 best paper ShanghaiTech (Jiayuan Gu, Jingyi Yu)
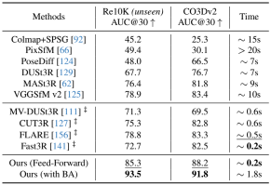
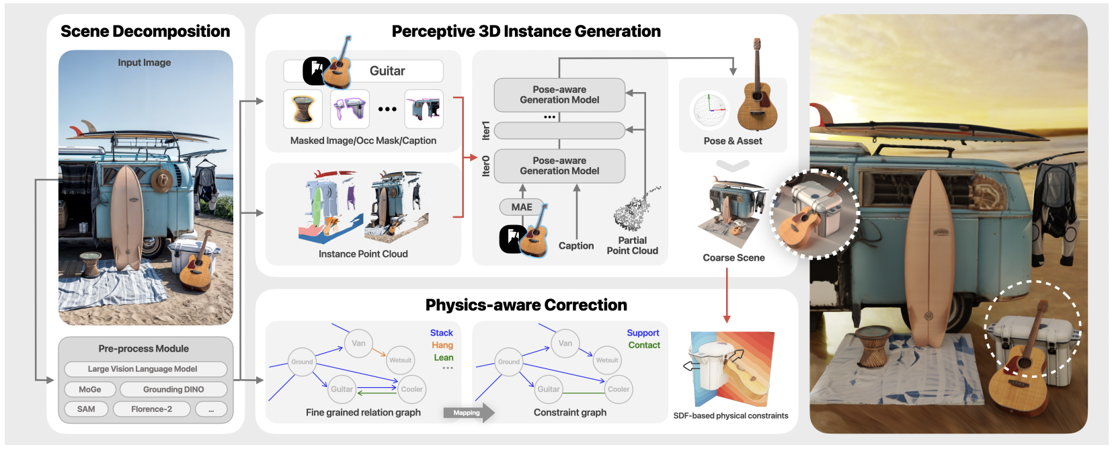
problem and position: 3D scene reconstruction from a single image where objects are posed precisely and interact naturally
method overview: use foundation models to first parse image, then diffusion-based generative model produces object meshes and aligns poses, and use inter-object relation as cost functions to optimize object poses
results:
method details:
first use foundation models to parse image
Florence-2 to detect objects with bounding boxes and descriptions
GPT-4v to filter out spurious detections and isolate meaningful objects
GroundedSAMv2 to get segmentation masks
MoGe to predict point maps
object mesh generative model builds upon 3DShape2VecSet, pre-train on Objaverse
VAE architecture, encode image and point cloud, diffusion on latent code, then decode as SDF
address occlusion by training with randomly masks
pose alignment diffusion-based generative model inputs scene point cloud and object latent code, outputs corresponding aligned-with-mesh point cloud
use Umeyama algorithm to recover the transformation matrix
iteratively alternate these two models, since initially no aligned-with-mesh point cloud available for object mesh model
further optimize object poses since not perfect estimated and not considered for inter-object relations
minimize custom costs depending on inter-object relations
contact-relation cost: encourage no penetration and at least one contact point
support-relation cost: encourage supported object stay close to the supporting
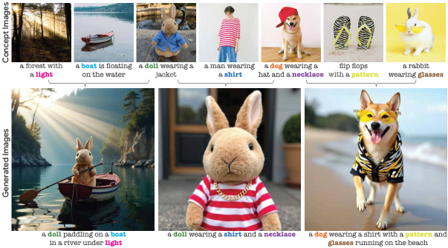
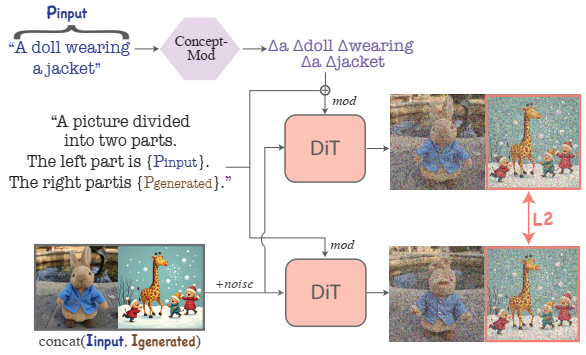
problem and position: generate combinations of multi-concepts from multiple images
method overview: learn modulation direction for each concept token by training an additional MLP to predict it then add it to modulate
teaser:
results:
method details:
intuitively add an attribute-aware direction to the modulation of all tokens, but not localized
so just add the direction to the modulation of the text token we want to affect
train Concept-Mod which is a small MLP to predict the direction for each token in concept image-text
training loss is the same as original diffusion loss, but add two tricks
50% training adds an additional concept isolation loss to encourage the learned directions not to influence other concepts not in the concept image, as L2 loss on a generated auxiliary image by added directions and original generation
additional MLP in each diffusion block to predict per-token per-block direction, added with per-token Concept-Mod
information: ICRA 2025 best robot learning paper finalist DeepMind
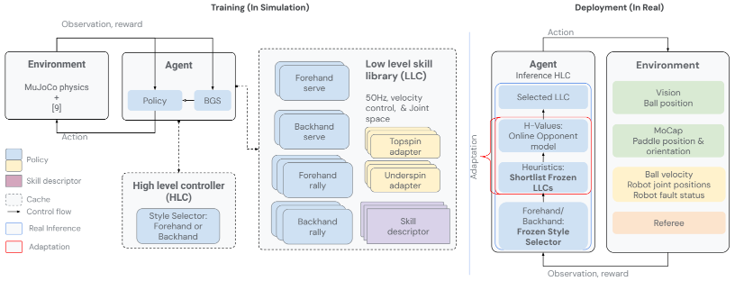
problem and position: first amateur human-level table tennis robot
method overview: high-level skill selector and low-level skill executors, train in simulation and iteratively transfer to real-world
results: robot won 13/29 matches with humans of different levels
method details:
use high-speed camera and perception to estimate ball position, use motion capture to track opponent’s paddle, in real-world
train in MuJoCo simulation with high-fidelity system identification and domain randomization, and iteratively train on evaluated real-world collected data with 7 cycles
state-based policy instead of vision-based, one episode as one hit
high-level controller select multiple low-level controller to execute
low-level controllers act at 50Hz for producing joint velocity
train in simulation by BGS
1D CNN, input 8 timesteps of ball 3D position and velocity and robot joint positions, output 8 timesteps of robot joint velocities
first train 2 generalist base policies for forehand and backhand styles, then finetune from them to specialist policies, leading to 17 skills
maintain skill descriptors like the performance metadata
high-level controller acts when opponent hits the ball within 20ms
train to predict forehand or backhand style, same input as low-level
train to classify topspin or underspin, input ball and paddle state
5 heuristic strategies to shortlist some low-level controllers
estimate and update online preference of each low-level skill
information: ICRA 2025 best human-robot interaction paper SJTU (Cewu Lu)
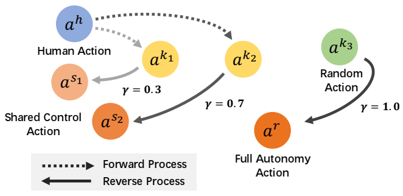
problem and position: human-robot shared control during teleoperation to reduce effort
method overview: first human operators teleoperate to gather initial dataset for training diffusion policy, then human-policy shared control by diffusing and denoising human action, and gradually increase policy control ratio, collect data while finetune policy