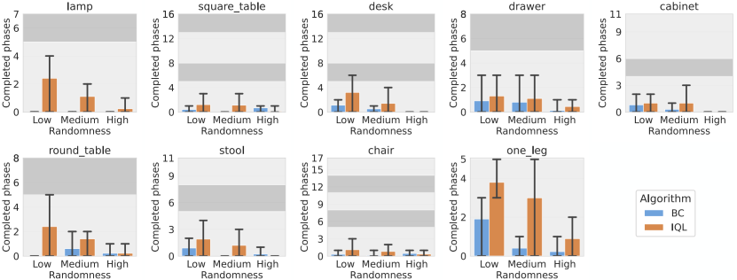
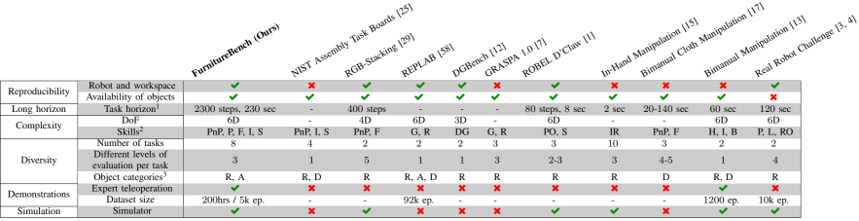
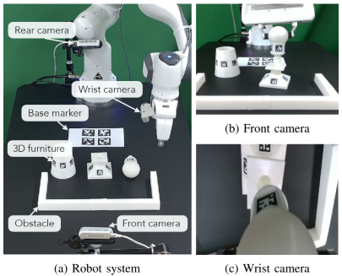
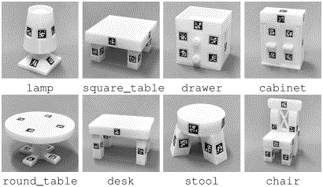
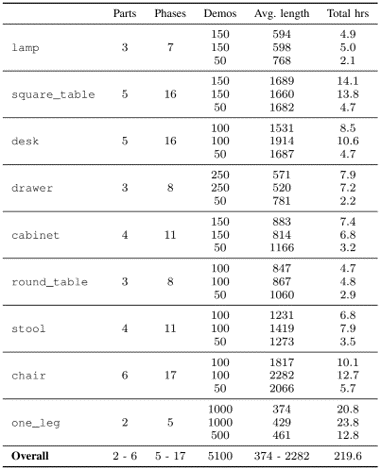
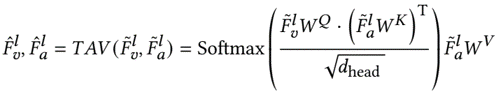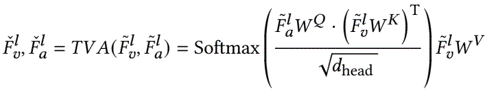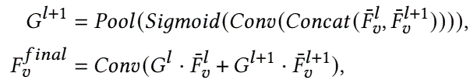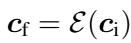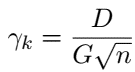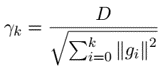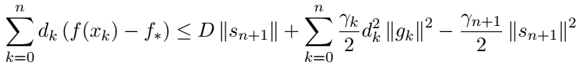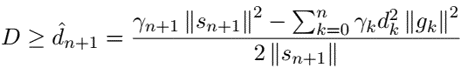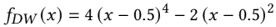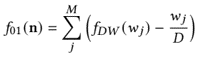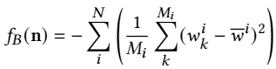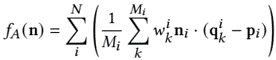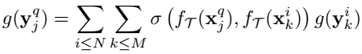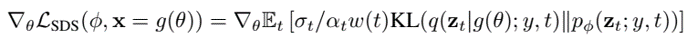information: NeurIPS 2023 outstanding paper Stanford
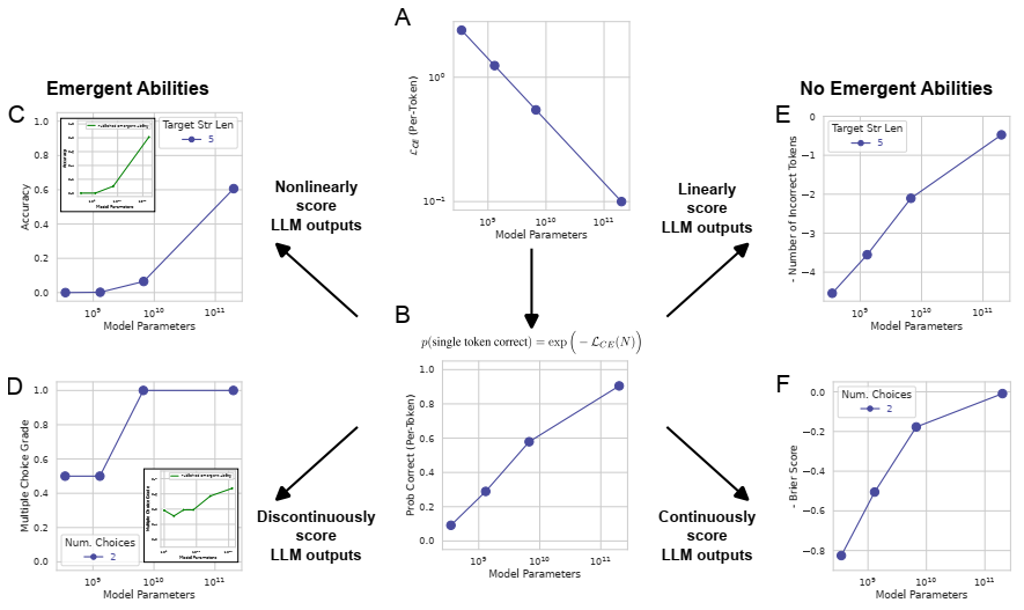
problem and position: analysis on the emergent abilities of LLMs
method overview: simple theoretical derivation using neural scaling laws and empirical experiments using different metrics
results: researcher choosing a metric that nonlinearly or discontinuously deforms per-token rates causes seemingly the emergent abilities, rather than fundamental changes in model behavior with scale
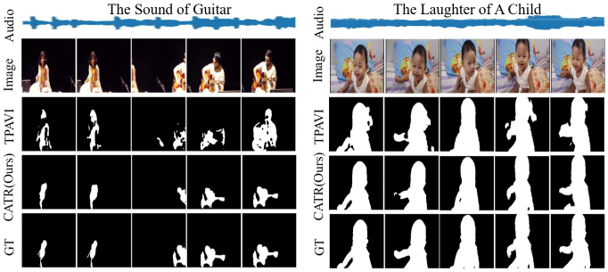
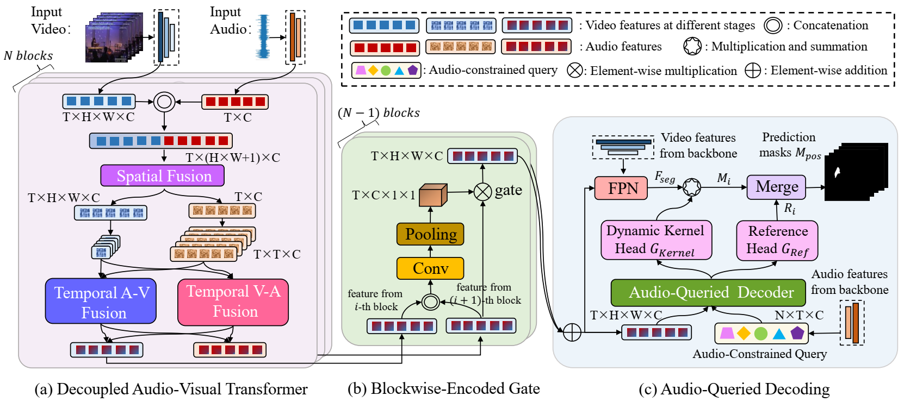
visual and audio features separately: $F_v^l \in R^{T\times H\times W\times C}$ and $F_a^l \in R^{T\times d}$
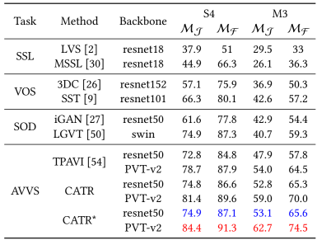
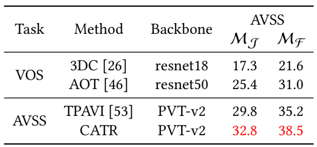
first visual extraction by ResNet-50 or PVT-v2 and atrous spatial pyramid pooling, first audio extraction by VGGish pretrained on AudioSet
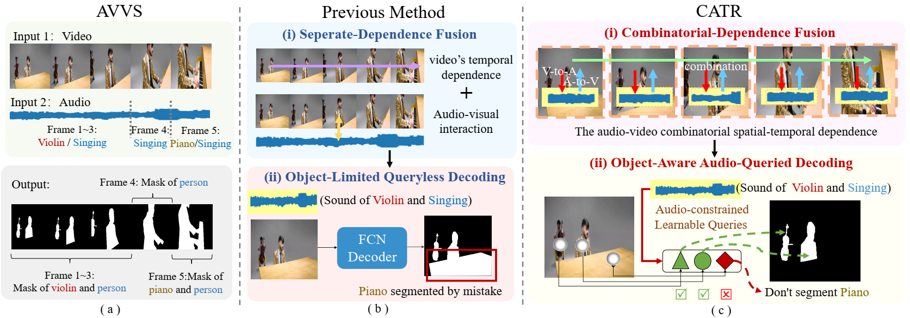
then spatial fusion by concatenating audio and visual features and self-attention on the mixed feature as $(H \times W + 1) \times D$
then temporal A-V and V-A fusion by multi-head attention alternating KQV as audio and visual features, merge by addition and only visual features are used for decoding
but spatial audio-visual fusion already mixes audio and visual features, why additional temporal fusions?
and inserted blockwise-encoded gate to propagate weighted features across different blocks
Audio-Queried Decoding
$N$ learnable queries $Q \in R^{N\times T\times C}$, embedding with audio features
visual features by FPN as $F_{seg} \in R^{T \times H/8 \times W/8 \times C}$
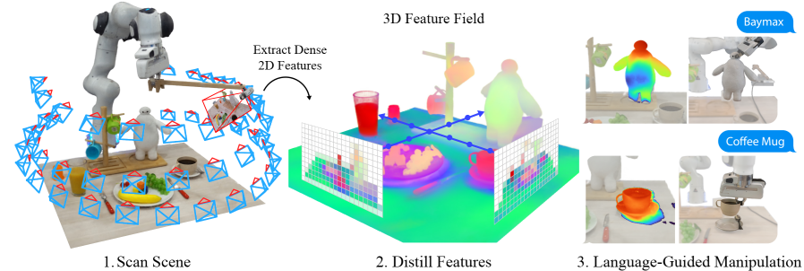
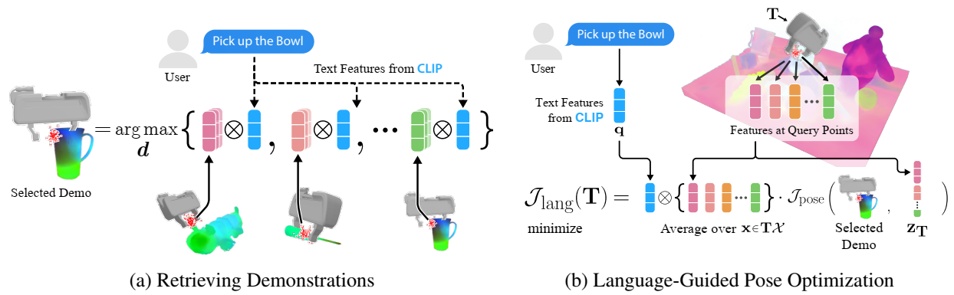
problem and position: few-shot and language-guided and open-ended grasping
method overview: NeRF learns CLIP features from 2D to 3D, use these features to find similar grasp poses from demonstrations or languages
teaser:
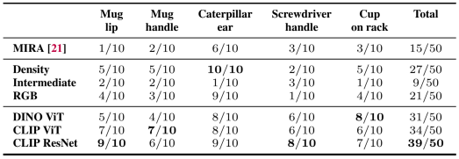
results:
method details:
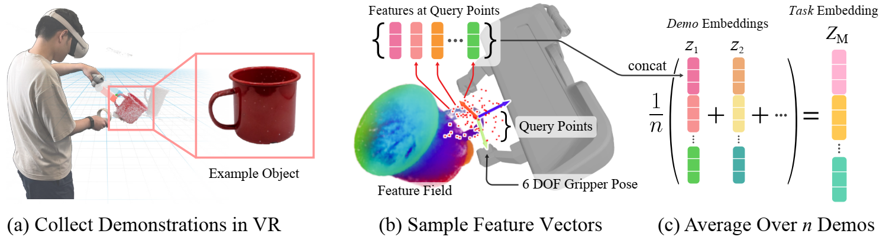
Distilled Feature Fields modify NeRF by additional feature output $f_{vis}$, supervised by 2D feature from patch-level MaskCLIP, each task instance train individually
demonstrations/dataset include the target grasp pose $T$, represent the target grasp pose as the average feature of sampled points around the grasp pose $Z_M$, each task category owns one
when inference for a new task instance, grasp pose is selected by choosing the discrete voxel having the feature $f_{\alpha}(v)$ most cosine similarity with $Z_M$ of the task category as translation, rotation by optimizing sampled rotations to minimize $z_T$ cos similarity with $Z_M$
for language-guided, the new task instance can have novel but similar object beyond the task category
when inference for language-guided, first retrieve demonstrations $z_i$ similar to the query text embedding $q$, then grasp pose is selected by choosing the discrete voxel having the feature $f_{\alpha}(v)$ most cosine similarity with $q$ as translation, rotation by optimizing sampled rotations to minimize $z_T$ cos similarity with $Z_M$ and also $z_i$
information: CoRL 2023 best systems paper Stanford (Huazhe Xu, Jiajun Wu)
problem and position: robot uses tools to manipulate deformable object like making dumplings and alphabet letter cookies
method overview: a little bit trivial, GNN models point cloud dynamics model, PointNet++ predicts tool selection and policy action and closed-loop control
teaser:
results: not standard benchmark, self comparison
method details:
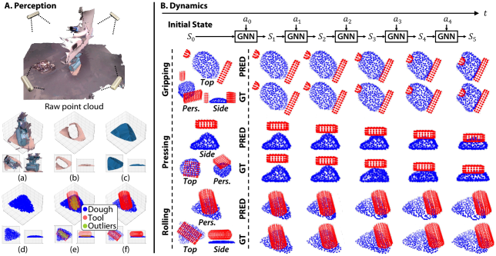
perception
merge RGBD point clouds from 4 cameras and crop the region of interest
color segmentation to extract dough points
surface reconstruction to a watertight mesh
use reconstructed mesh’s SDF to sample dough inner points
use tool’s gt mesh to sample tool surface points
dynamics model
GNN predicts future states of points based on the current states and action
vertex as point with its position and attribute
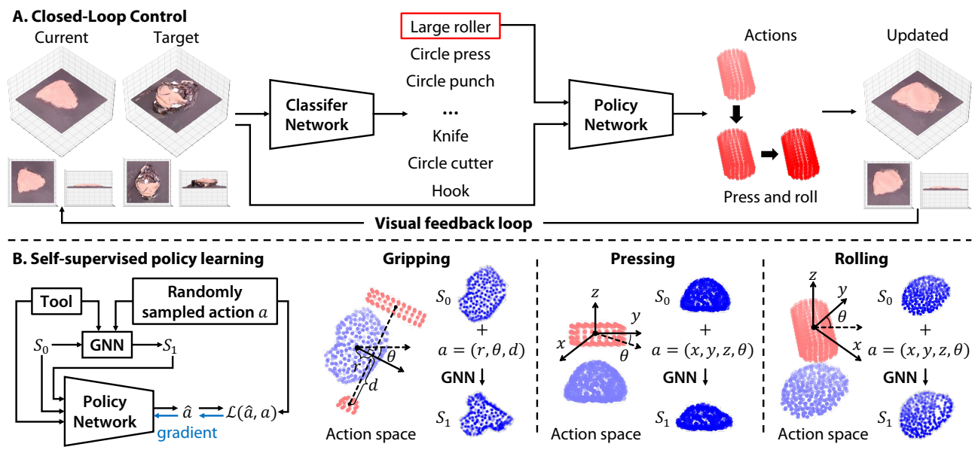
closed-loop control
PointNet++ based tool classification
PointNet++ based policy network, dataset synthesized by GNN dynamics model
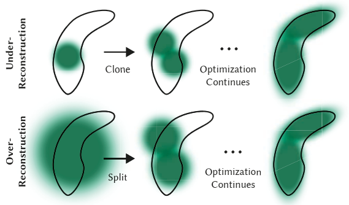
Gaussians can be bad for under-reconstruction and over-reconstruction cases, detected by large positional gradients, addressed by adaptive control either clone or split
rendering like rasterization, Gaussian as primitive
problem and position: neuro-symbolic approach for compositional visual tasks given natural language instructions
method overview: LLM generates high-level programs according to instructions and invokes subroutines to execute on the images
method details:
in-context learning of LLM: prompt GPT-3 with pairs of natural language instructions and desired high-level programs, avoid task-specific training, generate high-level python-like modular program
subroutines are predefined and invoked step-by-step
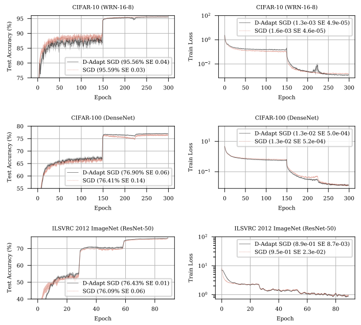
Distributed Data-Driven Predictive Control (DistributedDDPC)
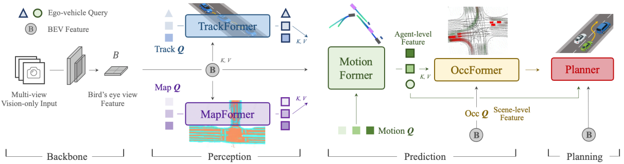
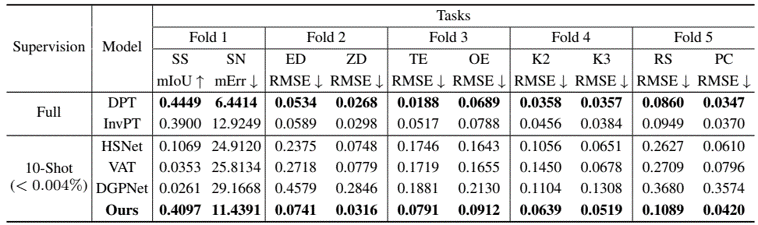
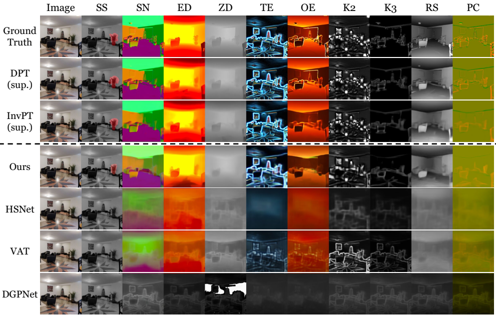
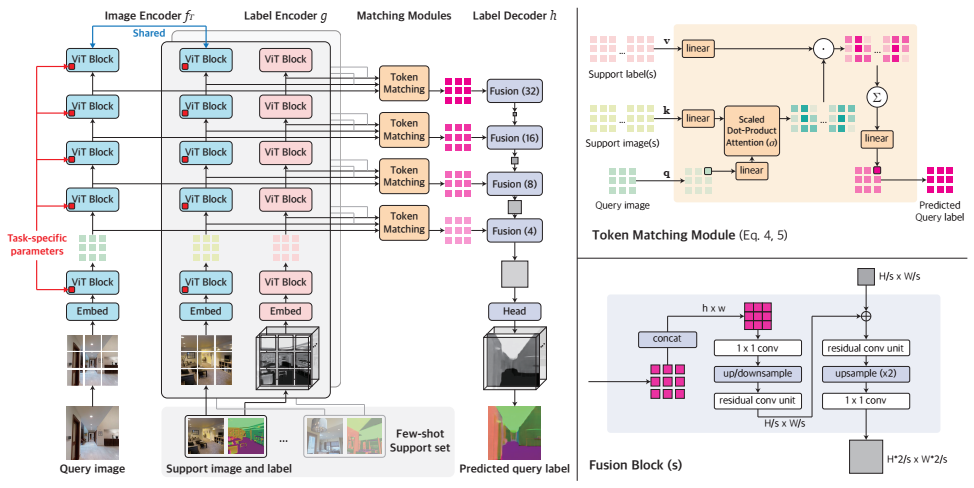
problem and position: the first unified few-shot learner for arbitrary dense prediction tasks
method overview: image patch similarity as weight to sum label embeddings
results:
method details:
episodic training on several tasks and test on unseen tasks
unseen tasks have different output structures: decompose $R^{H\times W\times 3} \rightarrow R^{H\times W\times C_T}$ into $C_T$ independent $R^{H\times W\times 3} \rightarrow R^{H\times W\times 1}$ and learn by shared model
query label as weighted combination of support labels in the context of embedding space
image encoder as ViT, initialized by pretrained BEiT
label encoder as ViT but from scratch
similarity function is implemented as scaled dot-product attention
label decoder as Dense Prediction Transformer but from scratch
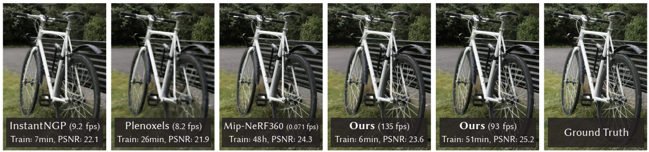
information: ICLR 2023 outstanding paper Google (Ajay Jain, Jonathan T. Barron, Ben Mildenhall)
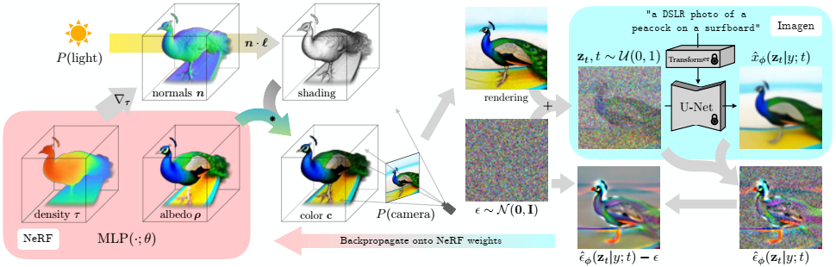
problem and position: transfer pretrained 2D text2image diffusion models to 3D object synthesis, without any 3D training data
method overview: propose a loss for updating NeRF weights to approximate text2image diffusion model generated image distribution
teaser:
method details:
Score Distillation Sampling (SDS): use KL divergence loss to update NeRF parameters $\theta$ so that generating $x = g(\theta)$ approximates sampling from the distribution modeled by diffusion model
diffusion model as Imagen with pretrained weights and frozen
NeRF as mip-NeRF 360 modified for additional shading, initialized with random weights and rendered under random camera and light
diffusion model can be thought as a teacher model to NeRF