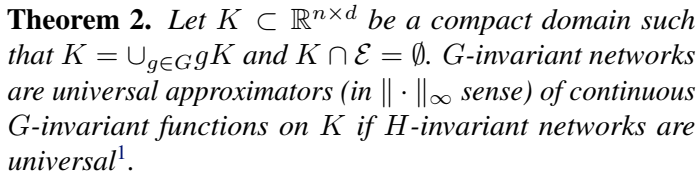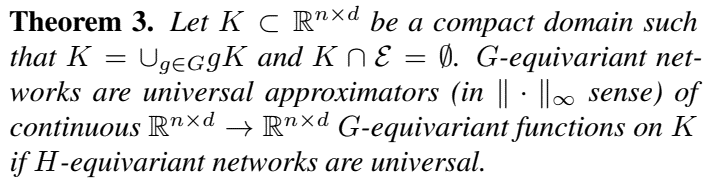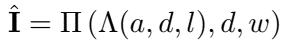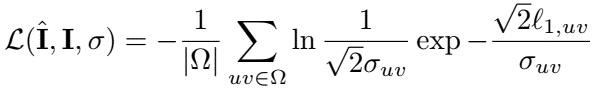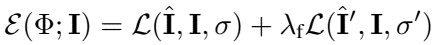information: NeurIPS 2020 outstanding paper OpenAI (Ilya Sutskever)
problem and position: want to remove task-specific finetuning for GPT after task-agnostic pre-training
method overview: scale up to 175B parameters and without finetuning but with in-context learning
teaser:
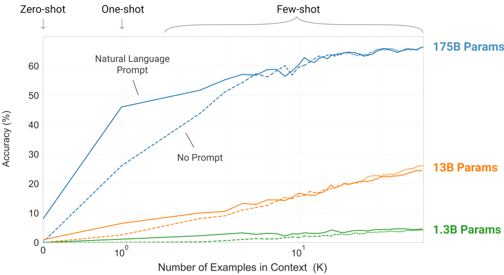
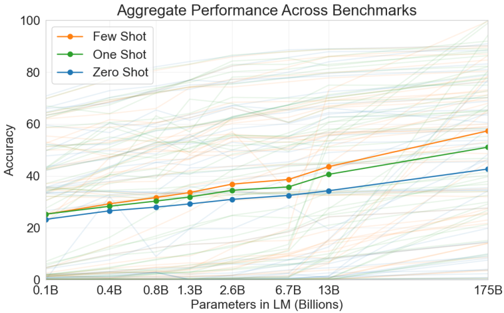
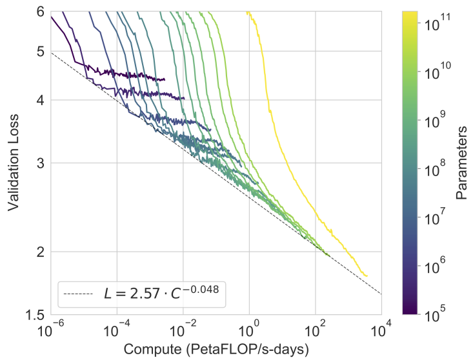
results: finding: while zero-shot performance improves steadily with model size, few-shot performance increases more rapidly, demonstrating that larger models are more proficient at in-context learning
method details:
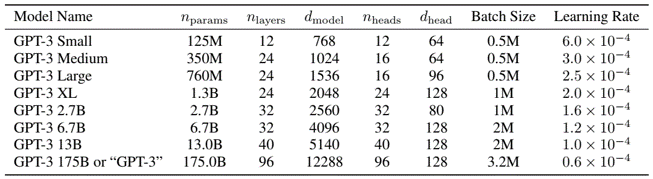
model are the same as GPT-2, just scale up
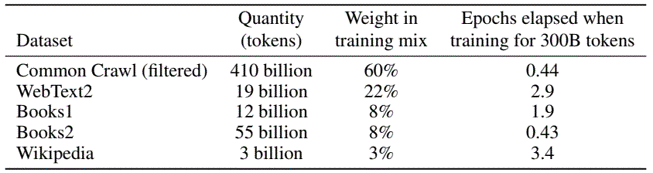
dataset from Common Crawl, but filter to improve quality and mix with other high-quality datasets, training not all but sample according to quality as weight for overall 300B tokens
training for larger model using larger batch size but smaller learning rate, loss almost log decreasing
information: CoRL 2020 best paper Stanford (Chelsea Finn, Dorsa Sadigh)
problem and position: learn latent strategy dynamics of other agent and then influence other agent’s strategy to achieve high cumulative reward across many interactions
method overview: autoencoder-like learn latent representation and RL learn policy conditioning on latent representation
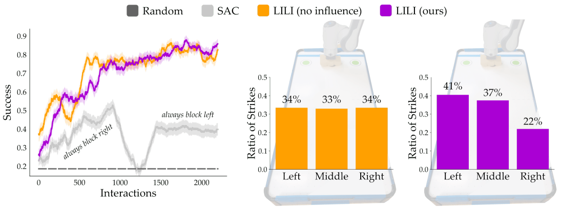
results:
method details:
many interactions with other agent, want to achieve high cumulative reward across interactions
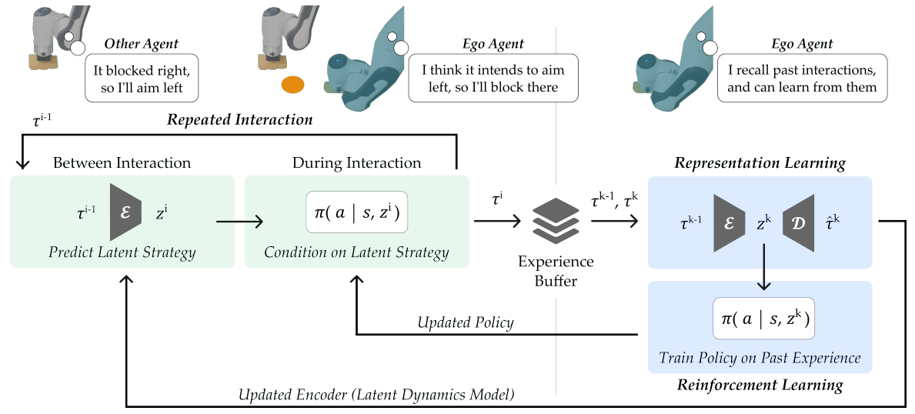
assume other agent’s high-level intention represented by latent variable $z$, during each interaction $z_i$ is constant but $z_i$ changes between interactions due to last ego agent interaction $\tau_{i-1}$, also influence this time ego agent interaction $\tau_i$
intuition is that ego agent can use its strategy to influence other agent to get long-term reward
latent representation learning: auto-regressive encoder $E(z^i \mid \tau^{i-1})$ and decoder $D(\tau^i \mid z^i)$, then $E$ can be used as latent strategy prediction
RL learns to action $\pi(a \mid s, z^i)$ conditioning on latent strategy and optimize cumulative rewards across interactions
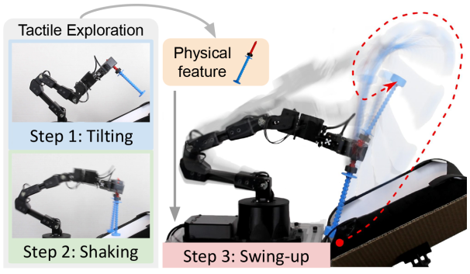
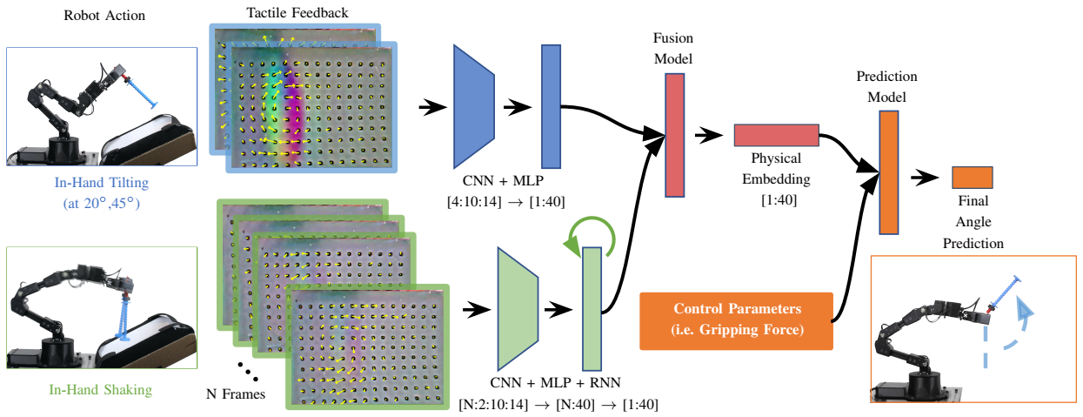
problem and position: swing up unseen objects to a specific pose
method overview: two exploration actions collect tactile information from GelSight and network extracts physical feature from the tactile information and network learns forward dynamics from the physical feature
teaser:
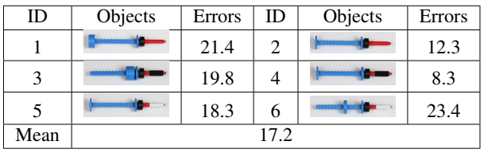
results:
method details:
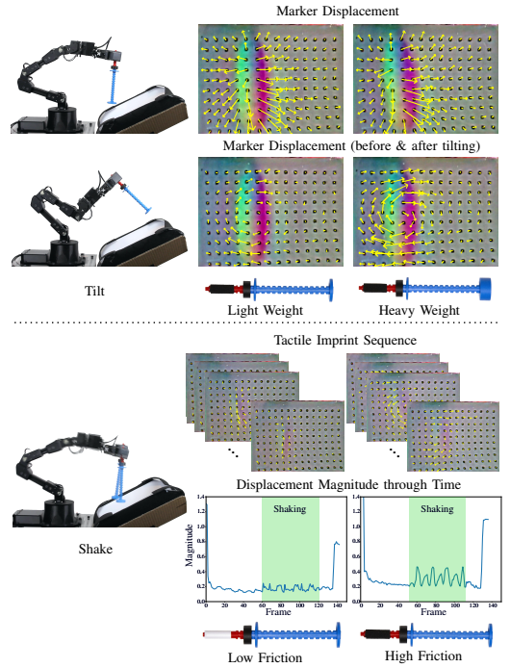
different physical properties lead to different tactile responses in tilting and shaking actions
tilting mainly for mass, center of mass and moment of inertia, shaking mainly for friction, but only in sense, actually no these physical properties explicit supervision
during training, the pipeline can be trained end-to-end since tactile data and control parameters as input and final angle as output all known
during inference, first do 2 exploration actions to collect tactile data, a set of control parameters are sampled, then choose output angle closest to target as chosen control action
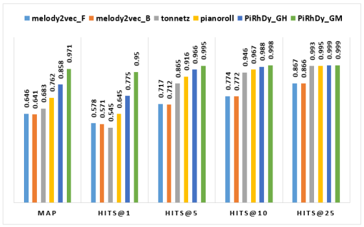
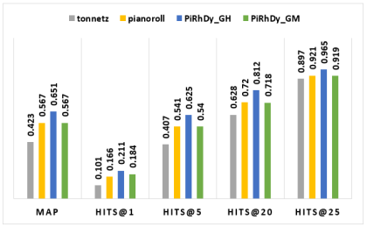
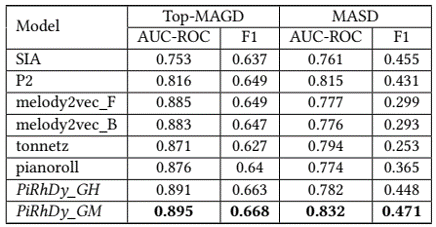
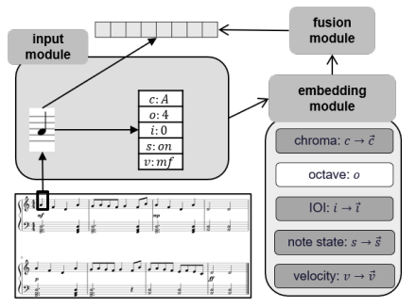
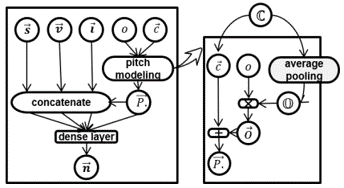
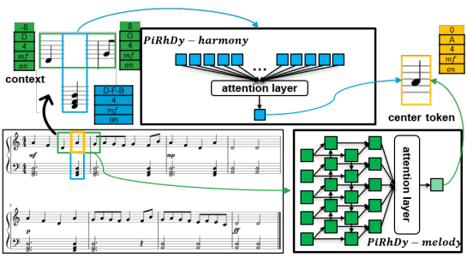
Pitch-, Rhythm-, and Dynamics-aware embeddings (PiRhDy)
problem and position: principled approach dealing with learning unordered set of general symmetric elements
method overview: prove principles of designing network for symmetric set elements
results:
method details:
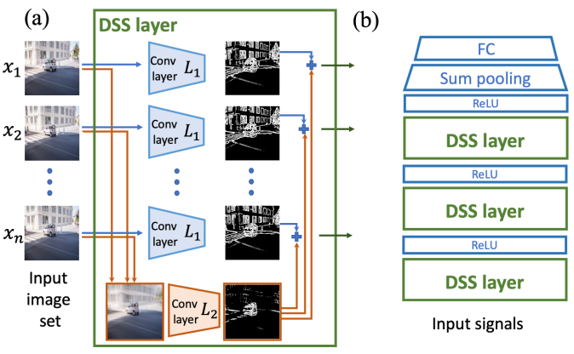
$X = {x_1, \ldots, x_n} \in R^{n \times d}$ symmetry equivariant groups $G = S_n \times H$: $S_n$ as permutation on $x$s order like reordering point cloud and $H$ as the same change on all $x_i$ like translating point cloud
$G$-equivariant network can be formulated as several $G$-equivariant layers $f = L_k \circ \sigma \circ L_{k-1} \cdots \circ \sigma \circ L_1$, then $G$-invariant network can be formulated on top of $G$-equivariant network $g = m \circ \sigma \circ h \circ \sigma \circ f$
function space is proven in Theorem 1, function expressive power is proven in Theorem 2 and Theorem 3
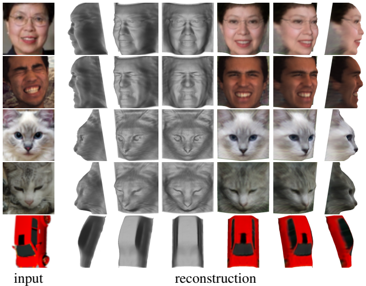
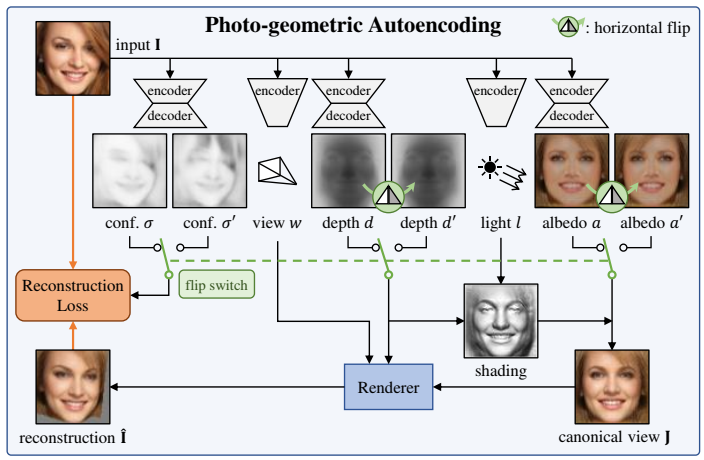
problem and position: reconstruct object’s depth, camera pose, lighting and albedo from single-view image without external supervision
method overview: autoencoder factors image into these components and use symmetry to constrain
teaser:
results:
method details:
mathematically reconstruct from these 4 components: lighting canonical view $\Lambda$ and reprojection to camera view $\Pi$
factoring without supervision is ill-posed: use symmetry in canonical view, horizontally flipping depth and albedo should lead to the same reconstructed image
symmetry is not perfect: also estimate a confidence map $\sigma$ expressing the uncertainty, and $\sigma’$ for flipped version
information: ICRA 2020 best robotic vision paper MIT
problem and position: existing non-minimal solvers for optimization rely on least-squares and cannot use robust estimation due to convexity constraint, so want to enable both simultaneously, as replacement for RANSAC
method overview: combine graduated non-convexity, Black-Rangarajan duality and non-minimal solvers to solve robust non-minimal problems, I cannot understand
results: test on 3 spatial perception applications, outperform RANSAC